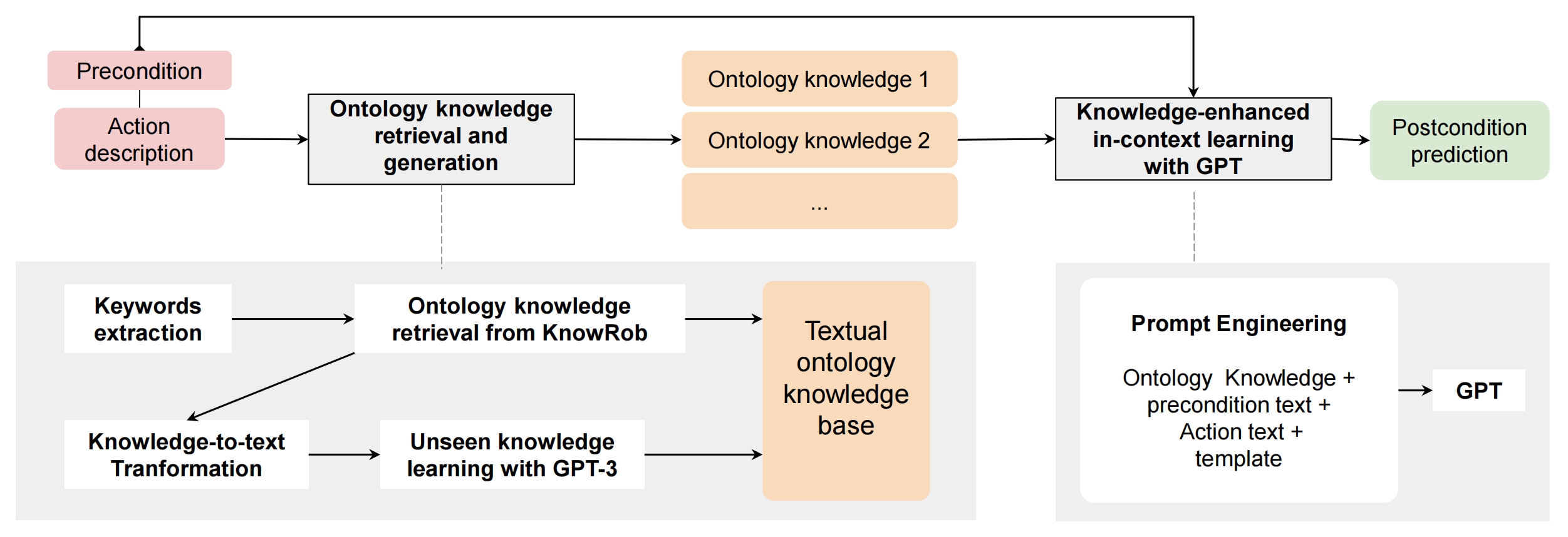
Ontology Knowledge-enhanced In-Context Learning
Introduction
We explore few-shot learning with large pre-trained language models based on a limited number of samples and propose task-relevant ontology knowledge (from KnowRob ontology) integration for in-context learning with generative pre-trained transformer (GPT) models. Specifically, we develop an ontology-to-text transformation to bridge the gap between symbolic knowledge and text. We further introduce unseen knowledge learning via GPT-3 to infer knowledge for concepts that do not have definitions in the knowledge base.
Ontology Knowledge
We employ KnowRob ontology as our knowledge source. It supplemented OpenCyc with additional knowledge about human everyday activities and household objects.
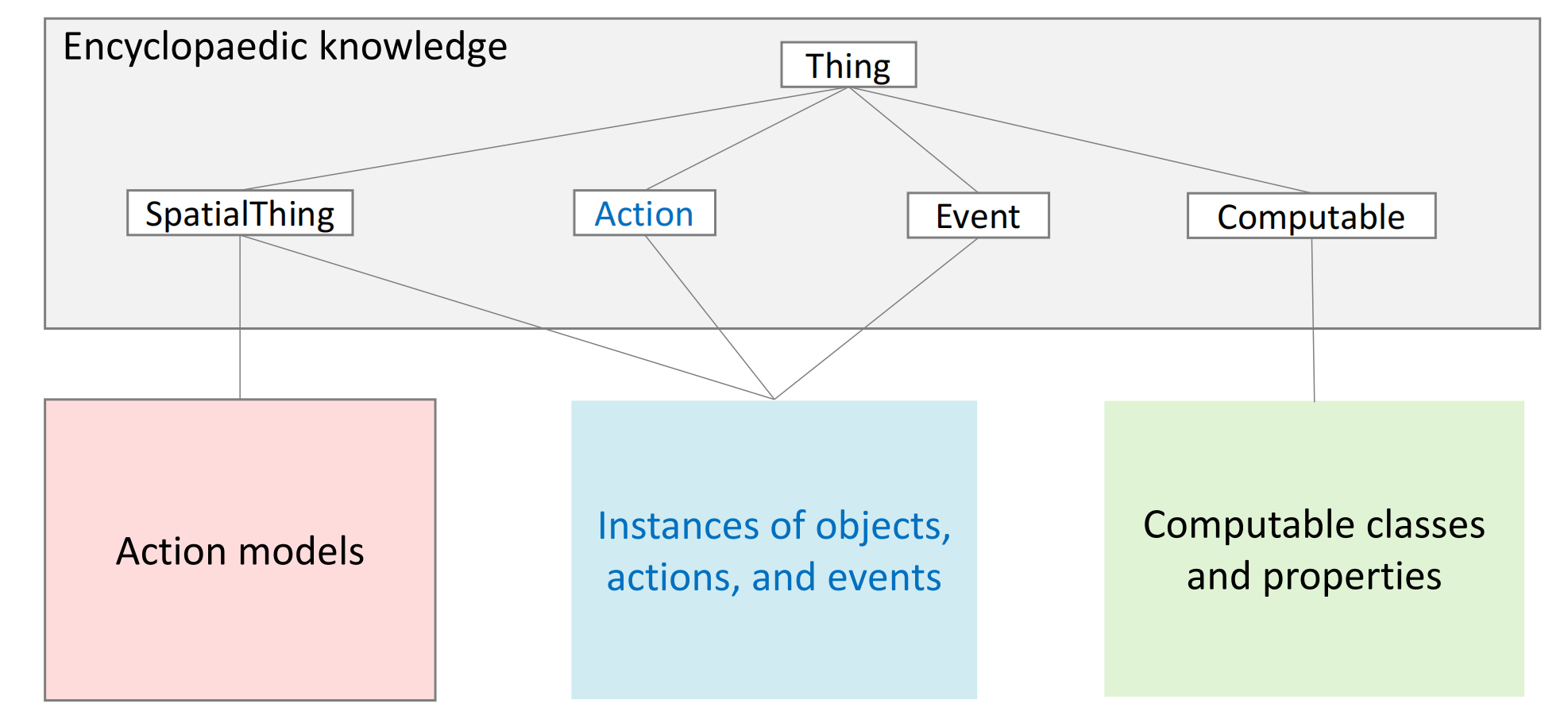
We develop this knowledge processing pipeline to solve two problems:
KnoRob ontology knowledge is intended for robot systems. How we apply such symbolic knowledge in LM is a critical component of our work. What we did is retrieval knowledge, then transform knowledge to text.
KnowRob is a fixed ontology knowledge base, thus has the knowledge incompleteness problem: there are no explanations for certain terms. How to obtain knowledge for concepts that do not have definitions in the fixed knowledge base and use them in LMs is a major challenge. To solve this problem, we conducted unseen knowledge learning with GPT-3.
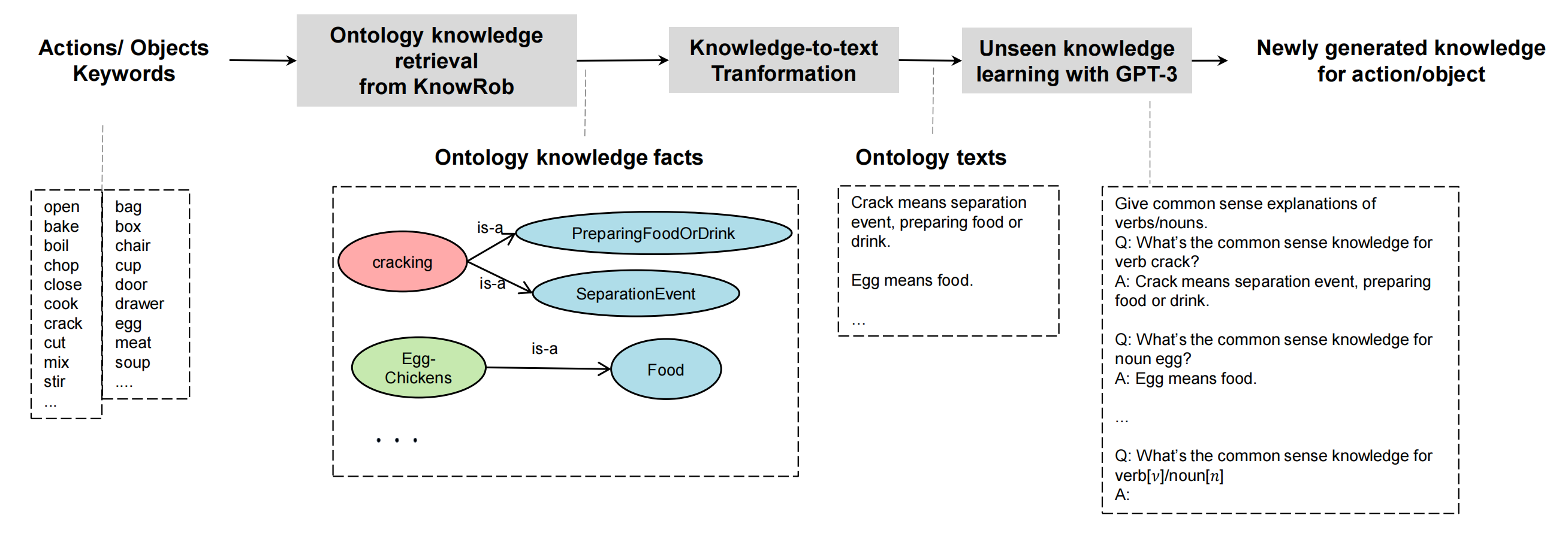
Knowledge Retrieval
We retrieve ontology knowledge for the verbs and nouns from KnowRob.The knowledge are stored in Web Ontology Language (OWL) triples (Subject, Relation, Object), the most common Predicate in the KnowRob ontology is subClassOf. We use verb and noun as Subject. Queried with SWI-Prolog using the querying method rdf_has(Subject, Relation, Object), It returns Object matches for all specializations.
- Subject – verb and noun from action phrases
- Relation – subClassOf
- Object – all matches

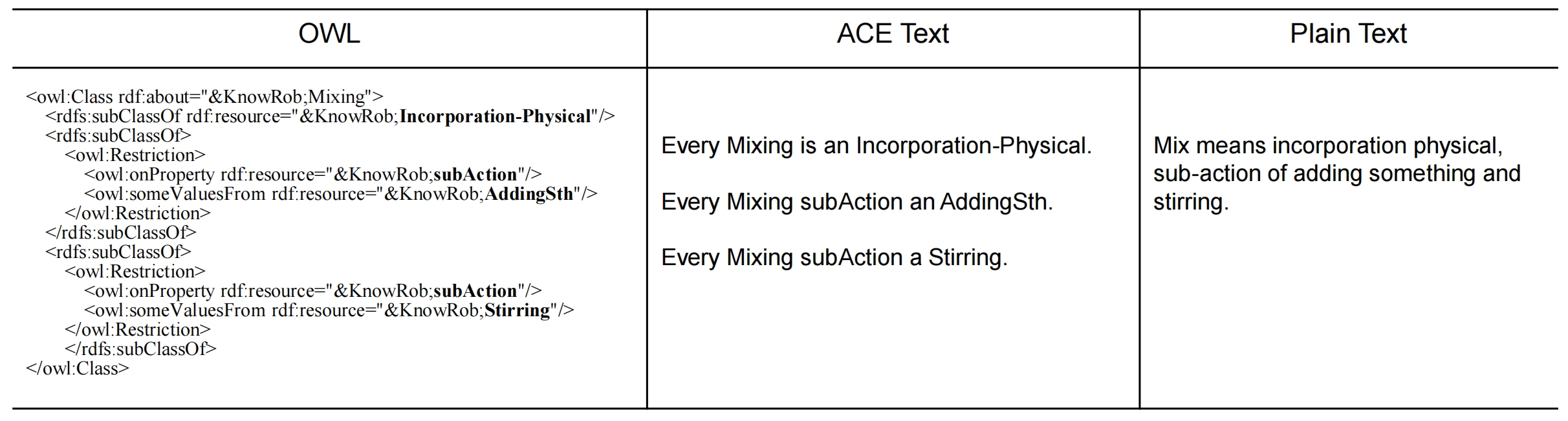
Knowledge-to-text Transformation
transforming XML-based format knowledge pieces to plain text. We map all retrieved OWL ontology fragments to Attempto Controlled English text use the OWL Syntax Converter and the OWL verbalizer tool, And then transform ACE text to plain text. We Insert a space before each uppercase letter, and convert all letters to lowercase; Removed the subClass descriptions Every and is a; replace abbreviation sth with something; and Concatenate all the texts to form a single sentence using a comma.
Unseen knowledge learning with GPT-3
How can we acquire knowledge assertions for terms that are not annotated in existing knowledge bases? We address the challenge by utilising GPT-3 to learn previously unknown ontological knowledge.
All retrieved knowledge for verbs and nouns form the A part of each Q-A pair.Given the task description, verb/noun examples and their knowledge definitions, expressed as the translated sentences from the second step along with the query prompt, GPT-3 will generate its version of knowledge for a new word.
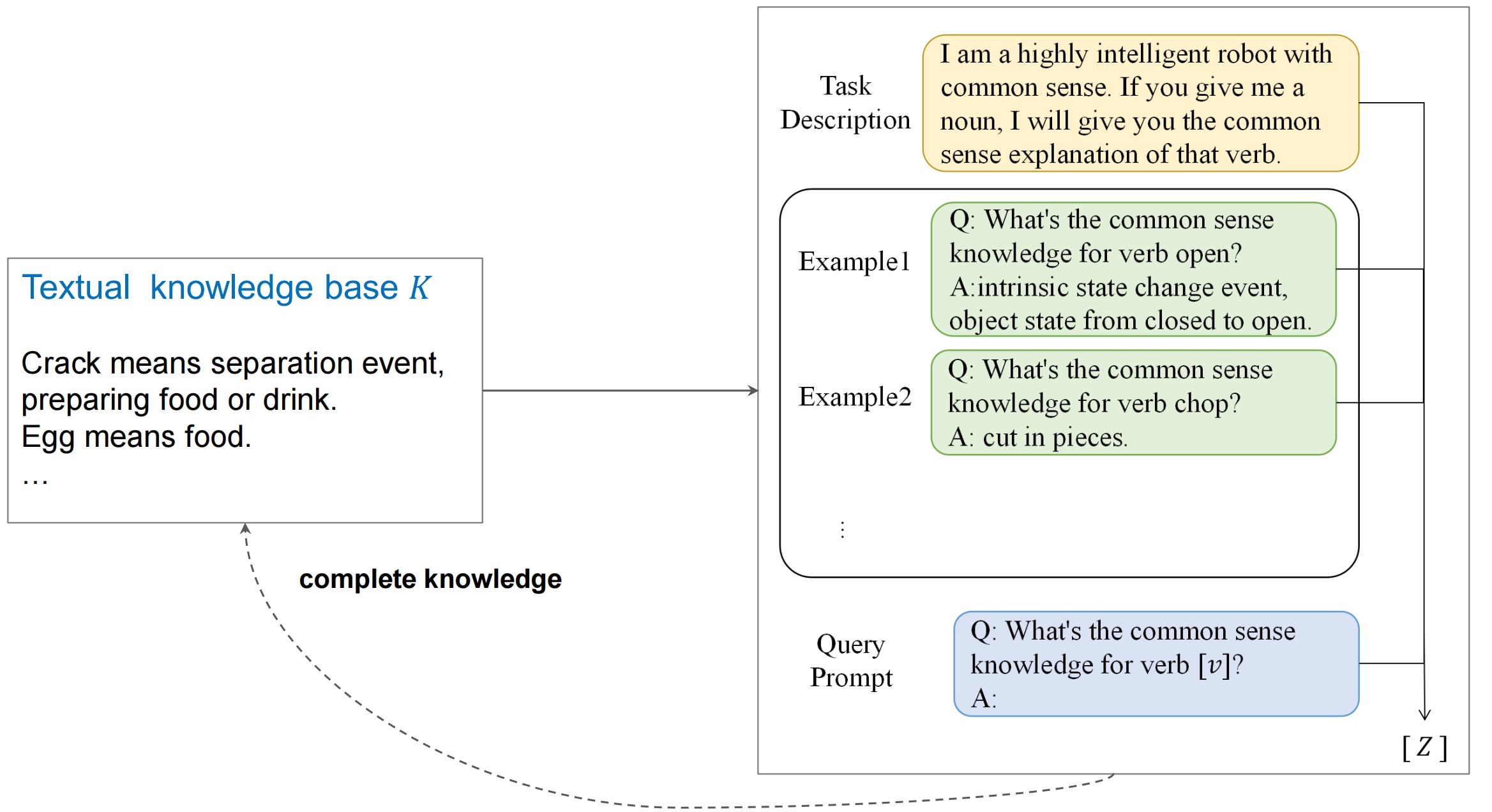
Knowledge-enhanced In-context Learning
The final work is embedding the knowledge into prompt. Since the generation of each word in a sequence is based on the word itself and all preceding words, we prompt the model with the knowledge statements by prepending knowledge pieces before action related descriptions.
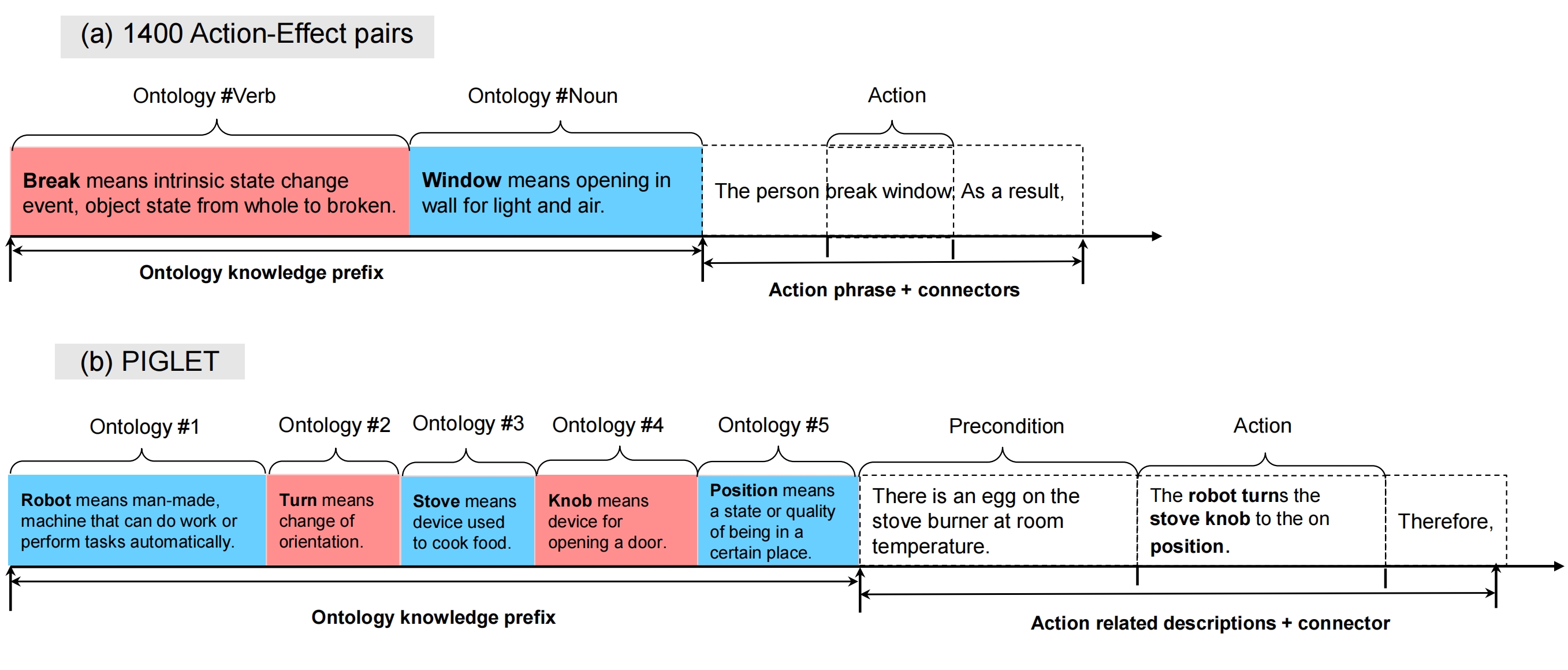
Here we present two instances for two datasets. The coloured boxes represent obtained ontology knowledge. break means…, window means… We begin by extracting a concepts list from description sentence usingmatching 1-grams. For example, for sentence The robot turns the stove knob to the on position, the exact matching result would be [robot, turn, stove, knob, position]. Then, we prepend these textual knowledge statements before the precondition sentence.
Experiment Results
In our experiments, four knowledge source settings are compared:
- pure LMs without external knowledge
- COMmonsEnse Transformers (COMET) [Bosselut et al, ACL 2019]
- ConceptNet graph [Speer et al, AAAI 2017]
- KnowRob [Beetz et al, ICRA 2018]
Evaluation metrics:
- BLEU measures the overlap between the generated responses and the ground truth [Papineni et al, ACL 2002]
- BERTScore evaluates text generation by computing token similarity with the BERT model. [Zhang et al, 2019]
We conducted few-shot learning (K=1,2,4,8). In the following table we show the results of GPT-3 Curie model. Better results in darker color. Best results for each shot in bold.
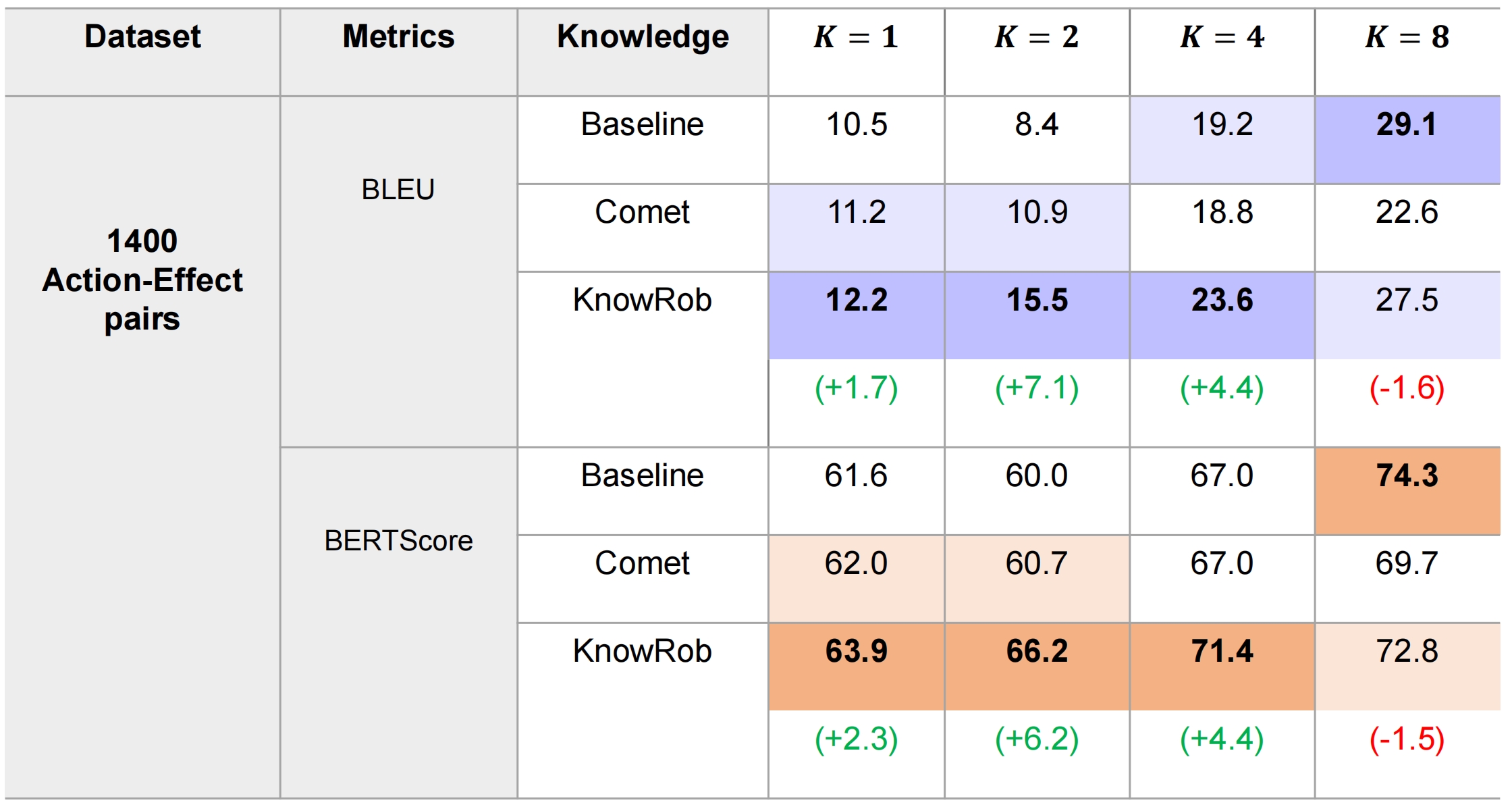 There is a trend of improving results when the in-context learning examples increases. For 1,2,4-shot, the prediction performance improves when exploiting completed ontology knowledge from KnowRob, especially for 4-shot learning. But when the training example increase to 8-shot learning, there is a slight drop with KnowRov for this dataset.
There is a trend of improving results when the in-context learning examples increases. For 1,2,4-shot, the prediction performance improves when exploiting completed ontology knowledge from KnowRob, especially for 4-shot learning. But when the training example increase to 8-shot learning, there is a slight drop with KnowRov for this dataset.
For PIGLET, There is an improvement of BLEU and BERTScore for all cases, but the increasement is not so obvious. 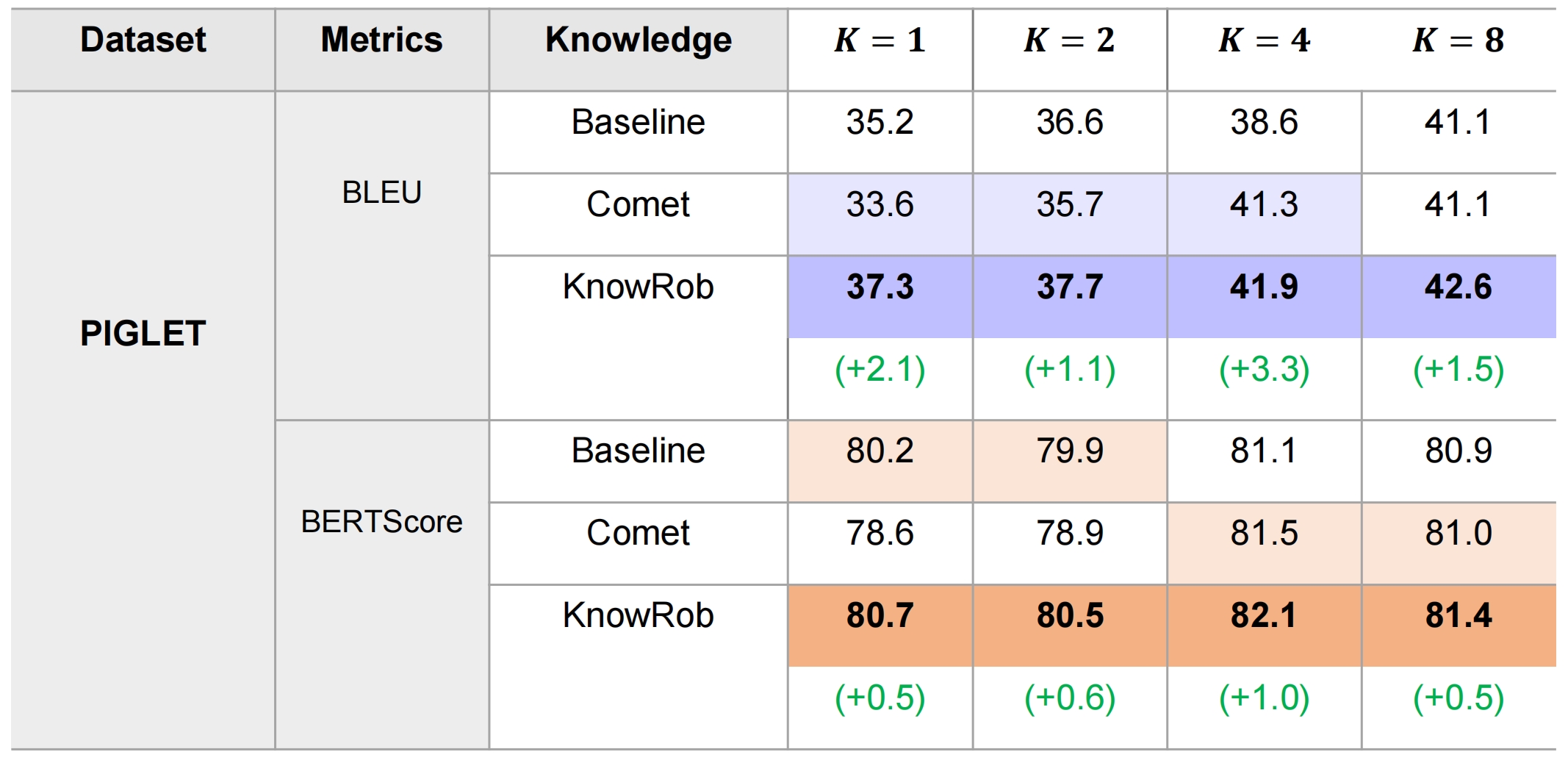
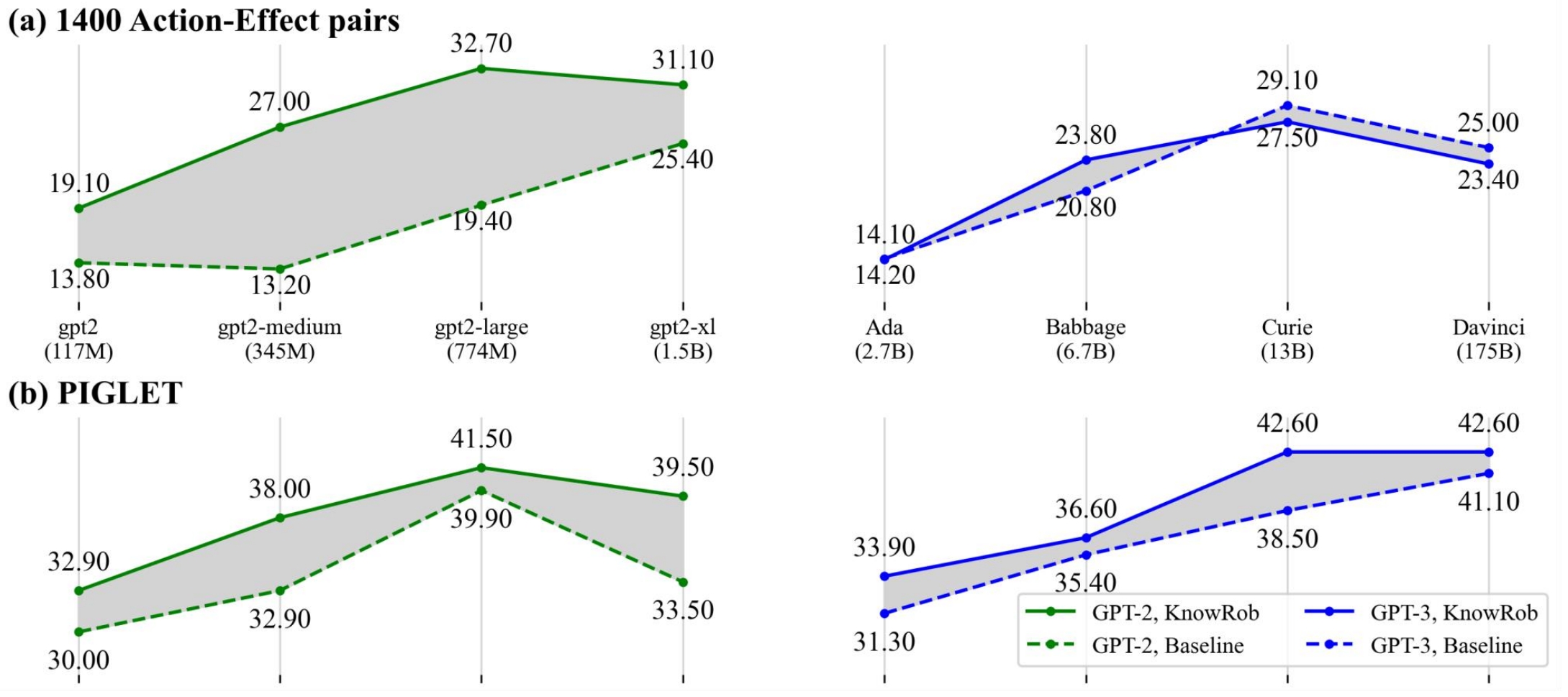
We then compared the 8-shot learning results on two knowledge settings: no external knowledge and with knowrob knowledge. We ran our experiments on four sizes of GPT-2 models (small, medium, large and XL with parameters 117M, 345M, 774M, and 1.5B) and GPT-3 models (Ada, Babbage, Curie and Davinci with parameters 2.7B, 6.7B, 13B, and 175B respectively).
On the whole, there is an increasing trend in BLEU performance scores when model size for GPT-2/ GPT-3 grows. For the 1400 action-effect pairs dataset, GPT2-Large has the highest BLEU score. Curie (the second largest GPT-3 model) got highest BLEU score among all GPT-3 models. GPT2-Large outperforms Curie for this dataset. The best results for PIGLET are obtained on the second largest size for GPT-2, but largest Davinci for GPT-3: But the BLEU score decreases when the model size is changed from GPT2-Large to GPT2-XL.
Conclusion
To sum up, we improved PLM’s reasoning ability by injecting external knowledge from a strongly relevant ontology KB: KnowRob. We form a bridge from a symbolic knowledge base to LMs by converting ontologies to textual prompts, thus demonstrating a new use for traditional KBs. Such a generation task has a broader application, e.g., robot manipulation, and combining this textual reasoning with visual information for further reasoning.